En el tutorial anterior, generamos una página web de hoteles que extrae una lista de habitaciones directamente con la fuente. Sin embargo, esto genera problemas en tiempos de respuesta para el usuario final. Sin embargo, llega a ser muy pesado para nuestro sitio web y para nuestros visitantes. Así que, nuestro objetivo es resolver la optimización de tiempos de respuesta del sitio con Web scraping automatizado.
Conociendo el proyecto
Como punto de partida, te comparto el código fuente del script para hacer scraping un sitio web de hoteles. El cual nos servirá de referencia:
¿Como funciona actualmente este proyecto?
El procedimiento funciona a través de una llamada síncrona, el sitio web finalizará una vez que el script obtenga los datos del portal de TripAdvisor.

De acuerdo a la línea de tiempo, desde que el usuario solicita información al sitio, éste recorre varios nodos haciendo varias peticiones para resolver el resultado final. Entre sus inconvenientes de este método, nos encontramos:
- El hecho de recorrer varios nodos, hace que el tiempo de respuesta sea más largo. Se genera una dependencia. Cuando se rompe en algún punto del camino, la experiencia del usuario sería poco agradable.
- Existiría una sobrecarga en nuestro servidor porque
cliente -> servidor -> fuentepara después,fuente -> servidor -> cliente. Al hacer esto todo el tiempo, hará que consuma muchos recursos del sistema cada vez que entra un nuevo usuario. - Regresando a las dependencias. No podemos controlar lo que hacen terceros. Si el equipo de desarrollo de TripAdvisor se le ocurre actualizar las vistas de sus sitios, inmediatamente nuestra página queda fuera de línea.
Todos esos casos pueden llega a ser críticos si llegaran a suceder. Lo más importante es poder ofrecer una excelente experiencia de usuario con los datos obtenidos de terceros. Para esto, requieres una serie de pasos para mejorar la salud del sitio web por medio de la automatización.
Uso de una base de datos
Para resolver estas observaciones, necesitamos cambiar un poco la estructura del proyecto. El objetivo será reducir los tiempos de respuesta para obtener las habitaciones más populares. Para conseguirlo, haremos uso de una base de datos que contenga la información necesaria para la consulta directa.
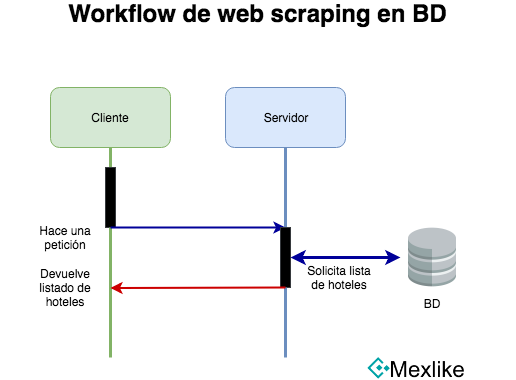
Con la información en la base de datos, el acceso a los datos es directo. Por lo tanto, el usuario no tiene que esperar a que el sitio haga un scraping a la página fuente. Para tener esa información actualizada necesitas un script que obtenga esos datos periódicamente para mantenerlo actualizado.
Pasos para realizar el refactoring del sitio web
Es hora de hacer refactoring al código que le hará scraping a la página de hoteles. Para esto necesitamos trabajar en varias etapas.
1. Generar la base de datos
Para la estructura, solo requieres una tabla que guarde la relación de habitaciones obtenidas. En mi caso, crearé un par de tablas para agregarle un poco más de información.
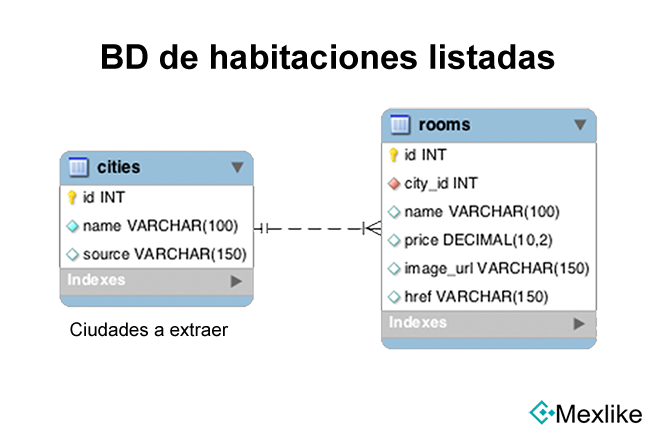
De acuerdo al diagrama anterior, existen dos tablas que nos servirán para este propósito:
- Cities: Esta tabla servirá para conocer las ciudades que queremos extraer. Cada registro cuenta con una url de cada fuente.
- Rooms: Guarda todas las habitaciones obtenidas del script, segmentados por ciudades.
2. Crear el conector de la base de datos
// File: connector.php
// Source: https://secure.php.net/manual/en/function.mysqli-connect.php
$mysqli = mysqli_connect(DB_HOST, DB_USER, DB_PASS, DB_NAME);
// Verifica si la conexión es correcta
if (!$mysqli) {
echo "Error: Unable to connect to MySQL." . PHP_EOL; echo "Debugging errno: " . mysqli_connect_errno() . PHP_EOL;
echo "Debugging error: " . mysqli_connect_error() . PHP_EOL; exit;
}
Si no existe un problema, la conexión de base de datos debería correr sin algún inconveniente.
3. Generar el scraper dinámico
// scraper.php
require 'simple_html_dom.php';
require 'connector.php';
require 'utils.php';
// Crea un objeto de funciones genéricas
$utils = new Utils;
// Antes de obtener nuevos datos, elimina los anteriores
mysqli_query($mysqli, "TRUNCATE TABLE `rooms`");
// Lista las ciudades: 1 => Isla Mujeres, 2 => Cancún, 3 => Playa del Carmen, 4 => Tulum
if ($result = $mysqli->query("SELECT id, source FROM `cities`")) {
/* Recorre todas las ciudades obtenidas para hacer scraping de esas ciudades */
while ($row = mysqli_fetch_assoc($result)) {
// Asigna valores a variables locales
$city_id = $row['id'];
$city_source = $row['source'];
// Crea el objeto DOM de la url fuente con el contenido
$html = file_get_html($city_source, false, null, 0);
// Todos los items de habitaciones fuente tienen esta clase
$wrap_hotels = $html->find('div.prw_meta_hsx_responsive_listing');
// Recorrer todos los contenedores de las habitaciones fuente
foreach($wrap_hotels as $element) {
// Guarda en variables locales, los datos específicos de cada habitación.
$hotel_name = $element->find('.property_title', 0)->plaintext;
// ¿Recuerdas la clase utils? Necesito quitar el formato MX$0.00 y convertirla a numérico
$hotel_price = $utils->format_price_to_int($element->find('.price', 0)->plaintext);
// También necesito obtener la url correcta con esta función prediseñada
$hotel_image_url = $utils->get_standar_image_url($element->find('.inner', 0)->attr);
$hotel_href = $element->find('.photo-wrapper a', 0)->href;
// Guardar esta habitación a la base de datos
mysqli_query(
$mysqli,
"INSERT INTO `rooms` (city_id, name, price, image_url, href)
VALUES ('$city_id', '$hotel_name', '$hotel_price', '$hotel_image_url', '$hotel_href')"
);
}
}
/* Liberar consulta */
$result->close();
}
/* Cerrar conexión */
$mysqli->close();
Puedes descargar las dependencias
simple_html_dom.phpyutils.php.
Como primer paso, recorrer la tabla ciudades. Indicará al algoritmo a que ciudades debemos acceder para obtener las habitaciones más populares. El algoritmo para extraer datos funciona igual, con la diferencia que almacenamos los resultados en la tabla rooms.
4. Programar el scraper para mantener los datos actualizados.
Lo que buscamos es delegar la funcionalidad de obtener y generar las habitaciones de manera independiente. Todos los resultados que extrae, serán almacenados en una base de datos. Cuando el usuario, haga una petición, consultará en la BD en vez de hacer el proceso de extracción directamente. Esto ayudará a administrar mejor los recursos del servidor.
Teniendo en cuenta esto, pasamos al proceso de programar tu script para que se repita en un periodo x de tiempo. La clave es mantener el proceso de generar datos de manera aislada como explico en el siguiente diagrama:

En la automatización, debes manejar los tiempos en base a tu criterio. En este proyecto, haré que el scraper se ejecute cada hora. Con este tiempo, considero, que es suficiente para mantener los datos actualizados sin tener que consumir demasiados recursos de mi servidor.
Este fue mi criterio:
- Si extendiera más el tiempo como a 4 horas, correría el riesgo de tener un mayor desfase de precios o incluso mostrar habitaciones que no están disponibles.
- Cuando reduces el tiempo, cada 20 minutos. Estaría empleando recursos del servidor cada 20 minutos para iniciar un proceso de actualización.
- Otra variable a considerar, es la cantidad de información que necesito procesar. Si necesitara obtener habitaciones de toda la zona sur del país, tendría que extender un poco más los lapsos de tiempo.
Para la automatización, usaré cron porque mis servidores están basados en Unix (Linux, FreeBSD, Mac OS, etc.). Si usas servidores windows, puedes configurar una tarea programada.
Ejecutar el scraper cada hora de manera indefinida
0 * * * * /usr/bin/php /YOUR/PATH/scraper.php &> /dev/null
Sino estás muy familiarizado con la sintaxis de cron, te recomiendo este post: Introducción a tareas programadas con cron. Ahí podrás ver como se define el formato de cada tarea.
5. Actualizar el llenado del template
Debido a que no hacemos scraping cada vez que el cliente solicita un listado de habitaciones. Accederemos directamente a las habitaciones almacenadas en la tabla rooms.
<div class="d-flex flex-wrap">
<?php if ($result = $mysqli->query("SELECT id, name, image_url, href, price FROM `rooms` WHERE city_id = 1")): ?>
<?php while ($hotel = mysqli_fetch_assoc($result)): ?>
<div class="col-lg-4 col-md-4 col-sm-6 col-xs-6 ">
<div class="wrap-box">
<div class="box-img">
<a href="<?php echo 'https://www.tripadvisor.com/' . $hotel['href'] ?>">
<img src="<?php echo $hotel['image_url'] ?>" class="img-fluid" alt="<?php echo $hotel['name'] ?>">
</a>
</div>
<div class="rooms-content">
<h4><a href="<?php echo 'https://www.tripadvisor.com/' . $hotel['href'] ?>"><?php echo $hotel['name'] ?></a></h4>
<p class="price">$ <?php echo $hotel['price'] ?> MX / Por Noche</p>
</div>
</div>
</div>
<?php endwhile; ?>
<?php endif; ?>
</div>
En realidad, no cambió mucho la sintaxis de como esta estructurado el template. La ventaja de realizar este refactoring es:
- Evitamos la dependencia directa del sitio original. Cuando realizan cambios en sus vistas, podemos actualizar nuestro scraper para adaptarlo a la nueva vista. Mientras tanto, la disponibilidad de nuestros datos no se compromete.
- Al tener los datos en nuestros propios servidores, hace que las rutas sean más cortas.
Para probar como funciona el proyecto final, te dejo el enlace para que puedas descargarlo: Proyecto Final
Consideraciones especiales
- La finalidad de este tutorial es conocer el funcionamiento de un scraper. Puedes usar un Framework PHP que te facilitaría más la vida. Sin embargo, prefiero evitar las distracciones que nos desviaran de nuestro propósito.
- Puedes optimizar más el proyecto por medio de carga asíncrona en el lado del cliente, por medio de ajax.
- Recuerda que tenemos habitaciones de cuatro ciudades diferentes. En nuestro proyecto, podemos agregar un dropdown que cargue dichas ciudades.
Espero te haya sido de utilidad este tutorial. Cualquier comentario que pueda complementar este post, sería bienvenido. Te agradecería mucho si nos ayudas a compartir este contenido para poder ayudar a otras personas.