En español se les conoce como arañas web, su función es rastrear todas las url que puedan encontrar a través de hipervínculos. Leen el contenido de los enlaces para después ir agregando las URLs a una lista según el algoritmos de cada robot. Los crawler, son creados frecuentemente por buscadores como: Google, Bing, Apple, MSN, Facebook, Twitter, entre otros.
La periodicidad para que el crawler visite tu sitio es proporcional a la frecuencia que actualizas o generas nuevo contenido.
Los crawlers siguen ciertas reglas de indexación

Los crawlers más frecuentes
Googlebot
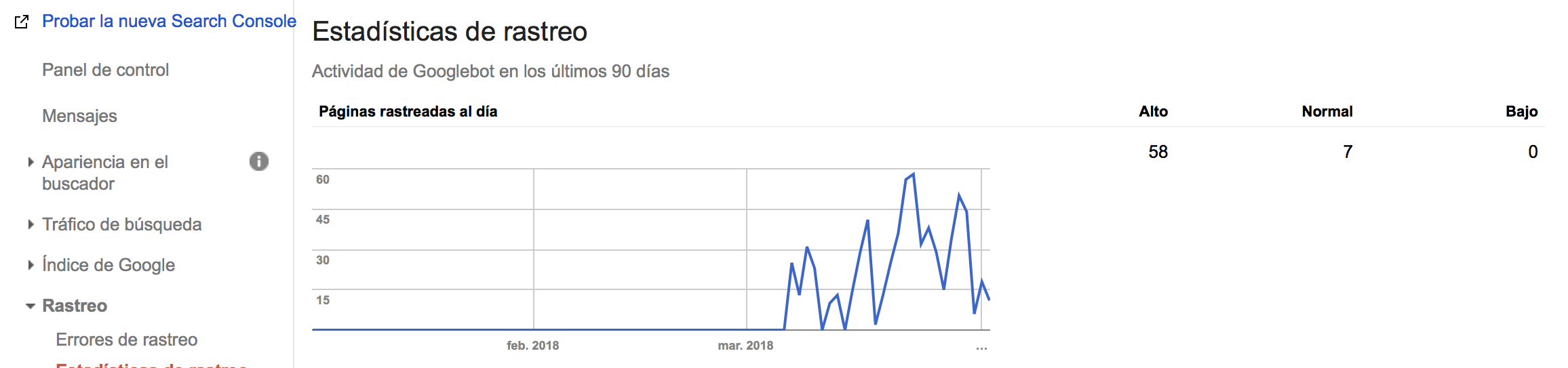
Como te podrás dar cuenta, Google Webmaster Tools solo almacena datos históricos por hasta 90 días. Pero esto deberías proporcionarle toda la información necesaria para descubrir los hábitos de rastreo de Google relacionados con tu sitio. En este caso, tenemos un promedio de rastreo de 7 páginas por día.
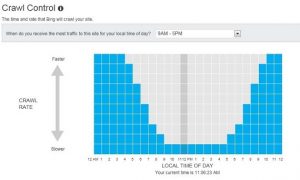
Bingbot
Applebot
Hace unos días, estaba revisando las peticiones que se realizan a Mexlike en el analytics de Cloudflare. Me llamó la atención de que existiera un bot llamada Applebot.

Según el sitio oficial de apple, es un agente de búsqueda utilizado para mejorar sus servicios a través de Siri y Spotlight. Aunque han surgido algunas dudas de su uso, porque apple ha solicitado sus búsquedas en índices de Bing y Wolfram Alpha. Solo podría deducir que apple siempre busca enriquecer su ecosistema de servicio con la calidad que los caracteriza sin depender de terceros.
Como Recomendación
Si quieres controlar lo que deseas que vean en tu sitio, te sugiero que sigas los estándares de robots.txt, así evitarás mandar información innecesaria que al final podría afectar tu reputación.
Espero haberte ayudado con esta información. Para cualquier alguna duda o sugerencia, quedaré al pendiente de tus comentarios. Agradecería mucho si me ayudaras a compartir esta información si crees que le podría servir a alguien más.