En internet existe una infinidad de información, es tanta la información que no podemos consumirla toda al misma tiempo. ¿Te imaginas extraer todos esos datos de manera manual recurrentemente? Por suerte, existen aplicaciones que buscan extraer datos, los procesan y ofrecen un información útil para nosotros. Este proceso se le conoce como web scraping.
¿En que consiste el web scraping?
Web scraping es una técnica utilizada, por medio de software, para obtener información pública de cualquier web. Esta técnica consiste en buscar fuentes que te proporcionen contenido para fines estadísticos o que mejoren la experiencia de usuario.
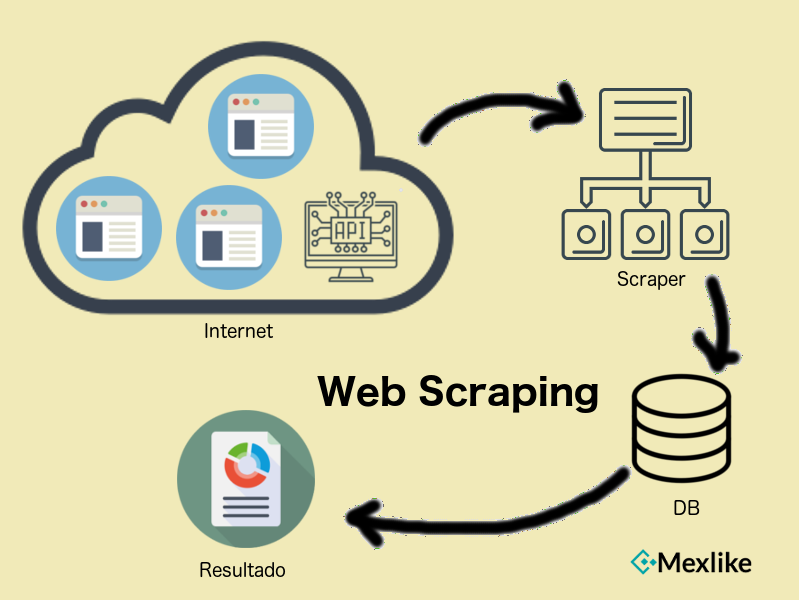
Este proceso puede ser único o periódico, dependiendo tus objetivos. Es una alternativa más ágil cuando necesitas obtener una gran cantidad de datos en periodo corto de tiempo. En el mayor de los casos es periódico, porque comúnmente se necesitan datos recientes.
El web scraping no promueve la ilegalidad
Debemos ver al scraping como una técnica que facilita una tarea específica como cualquier otra técnica. El uso que se le de, cambia la perspectiva de las cosas. Debemos pensar en la línea delgada entro lo legal y no. Pero eso depende del tipo de uso que le des. Recomiendo leer este artículo que habla respecto a ese tema: Web Scraping: ¿Legal, ilegal o depende?
Sus usos en la actualidad
Es común que nuevas startups basen sus operaciones en recolectar datos. Llegan a ser técnicas bastante explotadas en la fase inicial de las startups donde la información es crucial para la operación. También existen aplicaciones móviles que usan esa técnicas como los las apps de marcadores, de bolsa de valores y hasta asistentes para realizar tu despensa.
En lo personal he creado dos catálogos donde considero en mi experiencia para que podría servir esta técnica se se maneja adecuadamente:
Que tipos de datos se recomiendan extraer
- Datos efímeros como marcadores de futbol, tipos de cambios clima, acciones de La Bolsa de valores, etc.
- Reservaciones de hoteles de diferentes lugares.
- Encabezados de las noticias más relevantes. Podríamos generar un directorio y darle un uso inteligente a esa información.
- Contenido para fines internos solamente. Estadísticas, encuestas, opiniones de usuarios acerca de un tema en específico.
Que no se vale e incluso podría ser penalizado
- Obtener contenido original para replicarlo en tu sitio web.
- Datos que hagan una alusión personal, aunque sean públicos. Con los buscadores tenemos suficientes, incluso hasta Google ha tenido dificultades con noticias relacionadas a ciertas figuras públicas, conocida como El derecho al olvido, dictada por el Tribunal de Justicia de la Unión Europea.
- Datos personales como teléfono, correos, direcciones. Los puedes obtener para usos internos pero no los puedes explotar para enviar información al usuario. Las penas por realizar ese tipo de prácticas depende de la legislación en cada país.
¿Quiénes hacen uso del web scraping?
El scraping es una práctica tan común que son usados en las herramientas que frecuentemente usamos, como por ejemplo:
El mayor scrapper de todos los tiempos hasta ahora. Cuenta con un directorio de millones de páginas web que va indexando diariamente a través de sus crawlers.
Esta red social que ha tumbado dictaduras hace uso de las vistas previas. Twitter hace una extracción de datos básicos para poder mostrar un vista previa que mejore la experiencia de usuario.
Slack
A diferencia de las anteriores, slack es un sistema de mensajería en tiempo real creado para fines colaborativos. Incluso, prácticamente todos las apps de mensajería cuentan con esta función.

Con esto, te puedes dar cuenta que el scraping es una técnica muy útil para enriquecer la experiencia de usuario o incluso realizar estudios que mejoren esa experiencia. Una recomendación es que cuides la frecuencia que consultas un sitio en específico. Si saturas mucho las consultas de un sitio corres el riesgo de que tu ip sea bloqueada.
En futuros posts, te mostraré como realizar scraping con herramientas de terceros, también hacerlo de manera nativa por medio de scripts propios y por último como hacerlo por medio de librerías. Ninguna es mejor que otra, todo depende de las necesidades de tu proyecto.
Si te pareció útil esta entrada, te agradecería que me ayudes a compartirla. Cualquier duda u observación, nos puedes escribir en la caja de comentarios y será un placer poder intercambiar opiniones.