
El uso de estas técnicas te pueden ser de mucha utilidad. Con un fragmento de código puedes recorrer un sitio web de la misma forma que se presenta en un navegador. Puedes guardarlo en una base de datos o mostrarlo en alguna parte de tus sitios. Si deseas conocer más sobre sus usos, te recomiendo leer Introducción al Web Scraping.
Elección de Fuentes para los Primeros pasos de Web Scraping
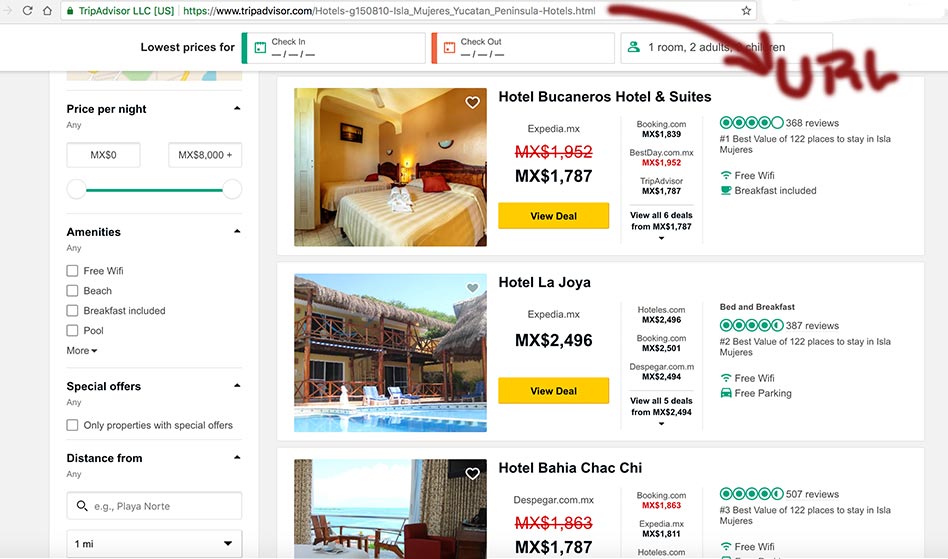
Como primer objetivo necesitas leer un sitio web externo para después embeberlo en tu propio proyecto, de eso trataré en esta entrada. En el Home quiero obtener los hoteles ubicados en Isla Mujeres desde TripAdvisor.
Lo primero que haremos es ir a la página de tripadvisor.com y realizar una búsqueda de hoteles de Isla Mujeres. No voy a seleccionar un Check In o Check Out porque a mí solo me interesa mostrar la relación de hoteles.

Una vez realizada la búsqueda, obtendrías resultados similares a la siguiente imagen. Se trata de un listado de hoteles de Isla Mujeres. Lo que nos interesa es tener la url con los parámetros necesarias que nos despliegue solo hoteles de isla mujeres.
Extraer un sitio con file_get_contents
Vamos a utilizar la url que obtuvimos para indicarle a nuestro script lo que queremos mostrar. Primero crearé el archivo scraper.php donde contendrá el script que leerá el sitio contenido de la URL señalada.
// Lee la url y obtiene el contenido en una variable
$html = file_get_contents("https://www.tripadvisor.com/Hotels-g150810-Isla_Mujeres_Yucatan_Peninsula-Hotels.html");
// Se imprime lo que obtuvimos en esa variable
echo $html;
Funciona, pero no siempre llega a ser así. Es necesario tener activado la directiva allow_url_fopen en el php.ini de tu servidor. Sino sabes como activarlo, te recomiendo que te des un clavado en este artículo sobre como activar allow_url_fopen en tu servidor.
Cuando trabajas de manera local, no parece ser un problema. Sin embargo, no todos los servidores dan privilegios de modificar sus archivos de configuración. Así que otra alternativa de poder tener los resultados en nuestro sitio es a través de cURL.
Extraer un sitio con cURL
cURL es una herramienta que te permite obtener información de distintos protocolos, además puedes hacer envíos de parámetros GET y POST. Su uso es tanta común que llega a ser utilizado en los crawlers para recolectar información de la web.
Por esas razones cURL es mi función predilecta porque me permite hacer conexiones. Incluso podría entrar a un área protegida por medio de mecanismos de autenticación.
La pregunta es ¿cómo hacer scraping para obtener un resultados similar al anterior? Realmente es muy sencillo, si bien requieres de más código para definir lo que quieres obtener realmente, lo podríamos encapsular en una función como lo haré en el siguiente ejemplo.
// Definimos la función cURL
function get_content_with_curl($url) {
// Inicial la función url
$ch = curl_init($url);
// No verifica el peer del certificado. Opcional
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
// Establece la sesión
$data = curl_exec($ch);
// Cierra la sesión
curl_close($ch);
return $data;
}
// Llamo la función previamente definida. La guardo en una variable por si deseo manipularla
$html = get_content_with_curl("https://www.tripadvisor.com/Hotels-g150810-Isla_Mujeres_Yucatan_Peninsula-Hotels.html");
// Imprimir la cadena recibida
echo $html;
Realmente lo que hicimos fue crear una función que nos permitiera obtener un sitio web, tal como lo lee un navegador, por medio de cURL. Con esto ya tenemos el sitio original en nuestro sitio.
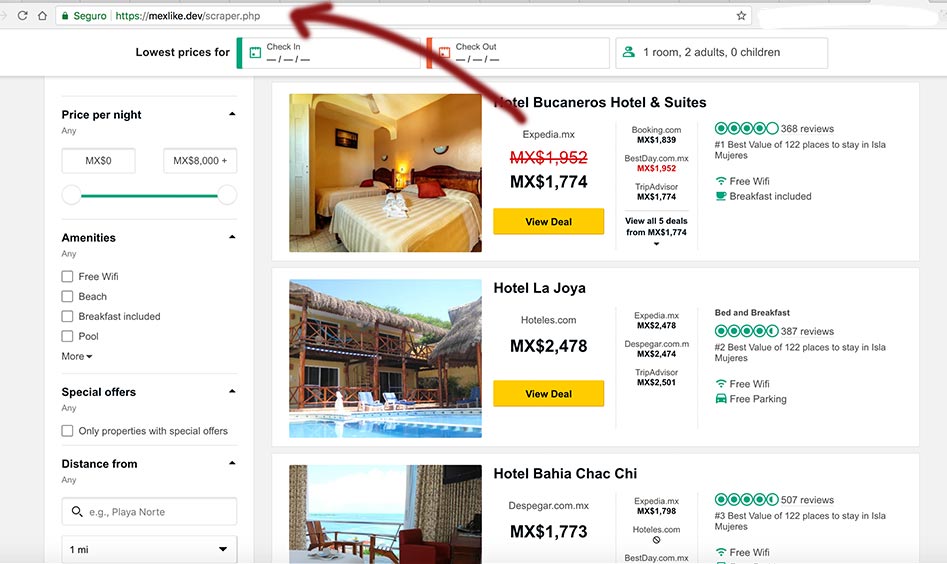
Resumiendo, el Scraping se basa en leer datos de otras fuentes. Aquí solamente leímos la web tal como está en la versión original, sin embargo, no le podríamos dar mucho uso de esta manera. Cada vez que requiera obtener datos de otras ciudades, solo llamaría esta función definida previamente. Para ser más selectivo en el contenido que obtenemos de cada sitio, es necesario desarrollar funciones más detalladas, sin embargo no es el objetivo de este post.
Como aclaración, hasta este punto aún no podemos darle un uso éticamente aceptable a esta técnica. Copiar contenido de otras fuentes y usarlo indiscriminadamente en tus sitios podría ser contraproducente. En el próximo post, vamos a especificar qué secciones necesitamos de los resultados que nos da TripAdvisor para nuestros proyecto con estilos propios.
Espero te haya gustado este post y/o te haya sido de utilidad, te agradeceríamos mucho si nos ayudas a compartir. Si tienes algún comentario, no dudes escribirnos en la caja de comentarios. Siempre estaremos ansiosos de intercambiar ideas con nuestros lectores.