En el pasado tutorial, hicimos una réplica exacta de una página con file_get_contents and cURL. Sin embargo, de esta manera no hay forma de sacarle mucho provecho. Corres el riesgo de que te reporten por plagio o confundan tu proyecto por una página de pishing. El objetivo de este tutorial es obtener las habitaciones más populares de Isla Mujeres con PHP Simple HTML DOM Parser y llenar nuestro template que hemos diseñado previamente con Bootstrap.
La fuente de información será TripAdvisor, uno de las guías más completas para cualquier viajero. Cada vez que accedamos a nuestro proyecto, un script leerá inmediatamente los hoteles más populares según la URL que le hayamos indicado.
Cabe recordar que este es un ejercicio de carácter educativo. No busco promover el plagio de información, sin embargo, existen usos totalmente válidos para esta técnica.
1. ¿Qué necesitas para empezar?
- Template del proyecto actual: Ver Template | Descargar Template
- Librería simple_html_dom.php: Descargar librería
- Versión de PHP 5+
Simple HTML DOM te permite extraer y manipular de manera fácil el html de un sitio web. De la misma manera como lo harías con jQuery o Javascript. Por eso es deseable estar familiarizado con el manejo del DOM en javascript.
2. Extraer la información de los hoteles con Simple HTML DOM
// Call dependency
require 'simple_html_dom.php';
// Create DOM from URL or file
$html = file_get_html('https://www.tripadvisor.com/Hotels-g150810-Isla_Mujeres_Yucatan_Peninsula-Hotels.html');
Hasta ahora, hemos extraído el contenido donde se listan los hoteles en TripAdvisor. Este contenido lo almacené en una variable $html para extraer la información que necesitamos. Hasta ahora tenemos una copia exacta de la página de referencia.
3. Identificar las secciones relevantes
Si necesitas obtener una sección del sitio de manera nativa, puedes hacerlo por expresiones regulares usando la función preg_match_all. Sin embargo, es una forma un poco más compleja porque requieres estar creando constantemente expresiones regulares. En este momento es donde Simple HTML DOM hace la magia. Lo que obtuve en la variable $html puedo manipularlo como un objeto a través de funciones definidas por la librería.
Aclarado esto, lo que necesitamos es identificar la sección que deseamos extraer del sitio de TripAdvisor. Esto es sencillo de realizar con el inspector de tu navegador. En mi caso utilizaré el inspector de Google Chrome.
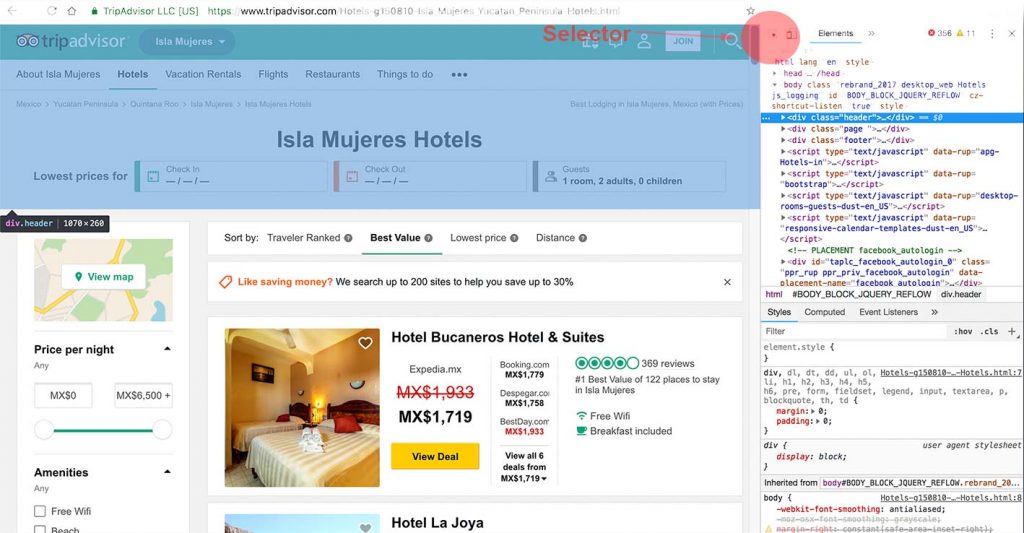
Con la herramienta de selección de chrome vamos buscando patrones. En el ejemplo anterior encontramos tres contenedores principales en la plataforma: .header, .page y .footer. En este ejemplo, pondremos atención en el contenedor .page donde esta la lista de las habitaciones que nos importan.
4. Extraer la lista de hoteles de la sección identificada
En este punto lo que queremos es buscar un patrón que identifique como obtener el listado de hoteles. Con el inspector identifiqué las secciones que me interesan:
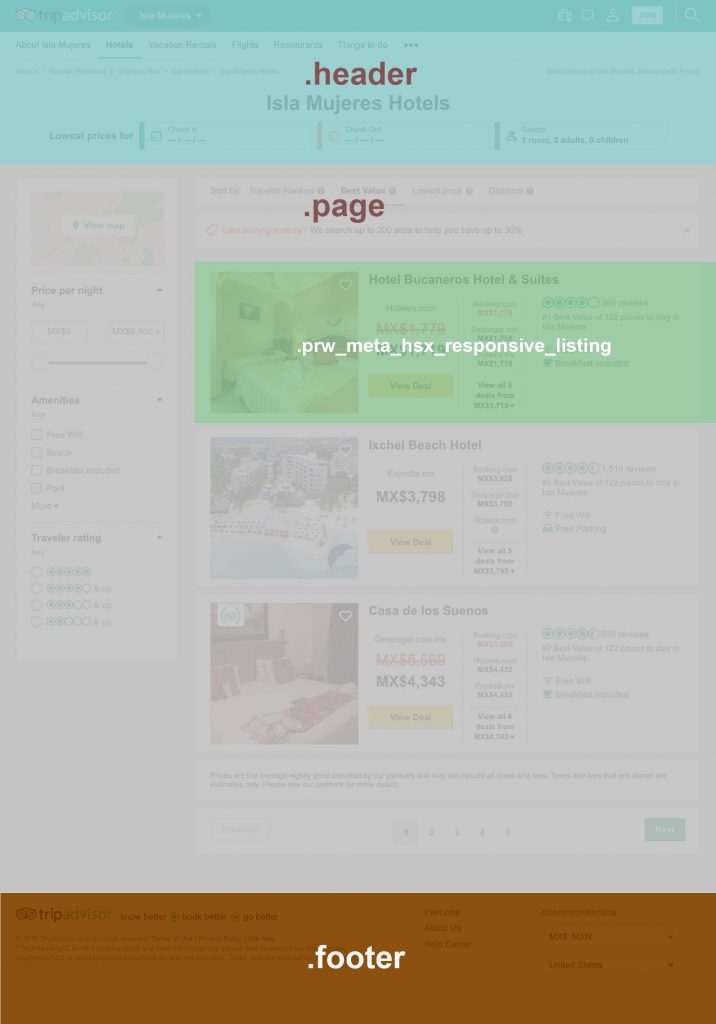
Como podrás observar, hemos encontrado un patrón que comparten todas las contenedores de cada habitación. Todas los contenedores tiene una clase llamada .prw_meta_hsx_responsive_listing. Ahora lo que necesitamos, es obtener toda la información que contiene cada caja con esa clase.
// De todo el contenido, solo necesito la lista de los contenedores de hoteles
$wrap_hotels = $html->find('div.prw_meta_hsx_responsive_listing');
Por medio de la función find, estamos obteniendo todos los contenedores que tienen la clase .prw_meta_hsx_responsive_listing. El resultado es un array que contenido la información interna de cada contenedor. Si haces un echo, el resultado sería algo similar a este:

Este array es una muestra de como se guarda la información. Por suerte, con las funciones de Simple HTML DOM nos facilita más las cosas.
5. Identificar las información específica de cada hotel
Ahora lo que necesitamos es extraer los datos específicos de cada hotel. Lo que nos interesa obtener según el template es:
- Nombre del Hotel
- La foto del hotel o departamento
- Precio
- Enlace para entrar a los detalles
Hacemos el mismo ejercicio pero en vez de inspeccionar toda la página de hoteles, inspeccionaremos solamente lo que esta en los contenedores que obtuvimos previamente de la clase .prw_meta_hsx_responsive_listing.
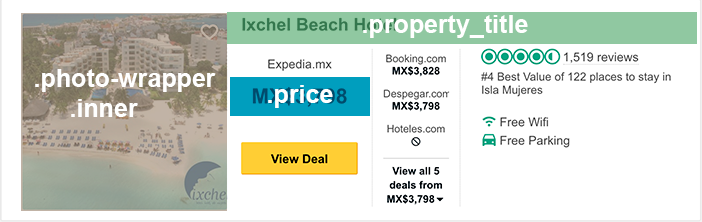
Identificadas las clases que contienen cada dato que necesitamos, lo primero que necesitamos es recorrer ese array para seleccionar el nombre, precio, imagen y enlace.
// Recorrer la lista de todos los hoteles obtenidos
foreach($wrap_hotels as $element) {
// Código para trabajar cada elemento
}
Tenemos en la variable $element los datos de cada uno de los hoteles, procedemos a obtener la información específica:
// Recorrer la lista de todos los hoteles obtenidos
foreach($wrap_hotels as $element) {
echo "<b>Nombre del Hotel</b> <br />";
echo $element->find('.property_title', 0)->plaintext . '<br />';
echo "<b>Precio</b> <br />";
echo $element->find('.price', 0)->plaintext . '<br />';
echo "<b>Url de la foto del hotel</b> <br />";
print_r($element->find('.inner', 0)->attr) . '<br />';
echo "<b>Enlace donde están los detalles del hotel</b> <br />";
echo $element->find('.photo-wrapper a', 0)->href . '<br />' . '<br />' . '<br />';
}
Aplicamos el mismo método find para leer el contenido de cada clase. Para obtener el nombre del hotel y el precio usé el atributo plaintext, para que no me muestre etiquetas html en mis resultados. Así funcionan estos atributos especiales:
// Ejemplos de extracción de datos
$html = str_get_html("<div>foo <b>bar</b></div>");
$e = $html->find("div", 0);
echo $e->tag; // Returns: " div"
echo $e->outertext; // Returns: " <div>foo <b>bar</b></div>"
echo $e->innertext; // Returns: " foo <b>bar</b>"
echo $e->plaintext; // Returns: " foo bar"
Para más información, puedes consultarlo en la documentación oficial. El resultado sería como en la siguiente lista.
Nombre del Hotel
Hotel Rocamar
Precio
MX$2,053
Url de la foto del hotel
Array ( [class] => inner [style] => background-image:url(https://media-cdn.tripadvisor.com/media/photo-l/0d/6b/4f/fb/hotel-rocamar.jpg); )
Enlace donde están los detalles del hotel
/Hotel_Review-g150810-d1477852-Reviews-Hotel_Rocamar-Isla_Mujeres_Yucatan_Peninsula.html
Nombre del Hotel
Hotel Plaza Almendros
Precio
MX$971
Url de la foto del hotel
Array ( [class] => inner [data-lazyurl] => https://media-cdn.tripadvisor.com/media/photo-l/08/7c/7c/9e/pool–v7986578.jpg )
Enlace donde están los detalles del hotel
/Hotel_Review-g150810-d616791-Reviews-Hotel_Plaza_Almendros-Isla_Mujeres_Yucatan_Peninsula.html
6. Caso especial. Como obtener la url de la imagen
/**
* @param Array $attr_image Atributos en forma de array
* @return Image URL
*/
function get_standar_image_url($attr_image) {
// Inicia la variable vacía
$url_image = '';
// Si el atributo es style
if (isset($attr_image['style'])) {
// Recuerda que el style nos da el formato así background-
image:url(URL_DE_IMAGEN)
// Usé substr para remover esos caracteres y solo dejarme la url como resultado
// Otra forma es usando regex
$url_image = substr($attr_image['style'], 21, -2);
// Nos proporciona bien la url
} else {
// Aquí nos da la url directa
$url_image = $attr_image['data-lazyurl'];
}
return $url_image;
}
Con la función que tenemos, vamos a realizar un refactory al código donde estábamos trabajando. Lo que haré por cuestiones prácticas es guardar los resultados en otro array que le llamaré $list_hotels con los valores que necesitaré para llenar mi template.
// Creo una nueva variable que guardara los datos que necesito para mi template
$list_hotels = array();
// Recorro el item original
foreach($wrap_hotels as $element) {
$hotel = new stdClass(); // Es más elegante usar objetos
$hotel->name = $element->find('.property_title', 0)->plaintext;
$hotel->price = $element->find('.price', 0)->plaintext;
$hotel->image_url = get_standar_image_url($element->find('.inner', 0)->attr);
$hotel->href = $element->find('.photo-wrapper a', 0)->href;
array_push($list_hotels, $hotel);
}
Ya obtuvimos el array que nos interesa, ¿ahora que sigue? Podemos trabajar con esa lista para llenar los datos del template del proyecto.
7. Llenar el template del proyecto
Con la ayuda de la variable $list_hotels, vamos a reemplazar nuestros cajas estáticas de nuestro proyecto local que tenemos alojados en CodePen. Tomaremos una caja donde muestra la información de nuestro proyecto.
<div class="col-lg-4 col-md-4 col-sm-6 col-xs-6 ">
<div class="wrap-box">
<div class="box-img">
<a href="#">
<img src="https://mexlike.io/wp-content/uploads/2018/06/Habitación-de-hotel.jpeg" class="img- fluid" alt="Habitación de Lujo">
</a>
</div>
<div class="rooms-content">
<h4><a href="#">Habitación de Lujo</a></h4>
<p class="price">$520 / Por Noche</p>
</div>
</div>
</div>
Puedo suponer que ya sabes que haremos con este proyecto. Vamos a repetir esa caja varias veces por medio de un loop. Nos caería de lujo usar foreach para este propósito, quedando de la siguiente manera:
<div class="d-flex flex-wrap">
<?php foreach ($list_hotels as $hotel): ?>
<div class="col-lg-4 col-md-4 col-sm-6 col-xs-6 ">
<div class="wrap-box">
<div class="box-img">
<a href="<?php echo 'https://www.tripadvisor.com/' . $hotel->href ?>">
<img src="<?php echo $hotel->image_url ?>" class="img-fluid" alt="<?php echo $hotel->name ?>">
</a>
</div>
<div class="rooms-content">
<h4><a href="<?php echo 'https://www.tripadvisor.com/' . $hotel->href ?>"><?php echo $hotel->name ?></a></h4>
<p class="price"><?php echo $hotel->price ?> / Por Noche</p>
</div>
</div>
</div>
<?php endforeach; ?>
</div>
Una vez que recorras el array $list_hotels que generamos resultado del web scraping. Tendremos este grandioso resultado:
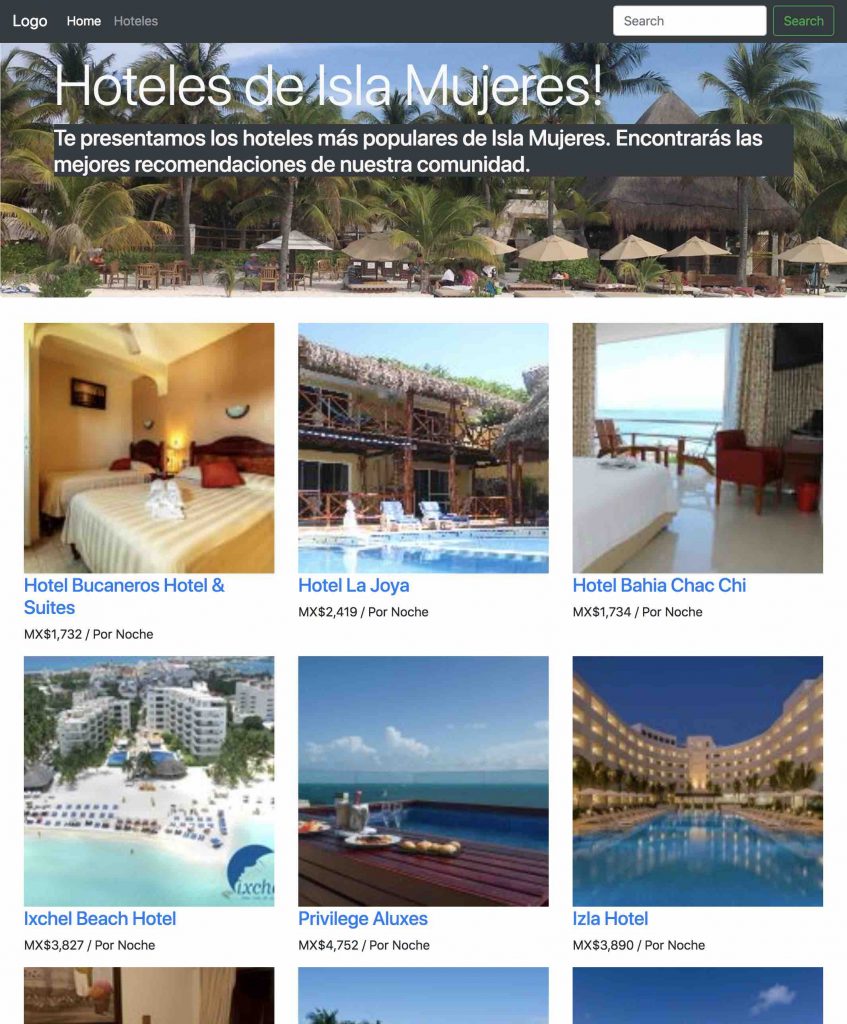
A partir de ahora, tenemos un listado de 30 hoteles de Isla Mujeres en nuestro sitio web. Lo podemos mostrar en nuestra página web. También pudimos hacer scraping a las páginas destino de cada hotel, pero haría mucho más complejo este tutorial. Si deseas probar como funciona, te dejo el resultado de este ejercicio:
Consideraciones especiales
- Cuando necesitas extraer un sitio con demasiada información, la librería te llega a limitar. Para aumentar esa limitación, puedes entrar dentro de la librería simple_html_dom.php y modificar la constante MAX_FILE_SIZE. Más información
- En el anterior punto no siempre es recomendable modificar fragmentos del código. En especial para los que trabajamos con composer, porque las actualizaciones borran tus cambios.
- Hicimos dos foreach: El primero tuvimos que obtener datos específicos para guardarlo en otro array y en el segundo caso para usar ese mismo array para llenar las cajas de nuestro proyecto local. Para optimizar el rendimiento, debimos llenar las cajas desde que obtuvimos los datos de los hoteles sin necesidad de crear otro array. Pero se justifica en el siguiente punto.
- Intentar leer la página fuente cada vez que accedemos a nuestro proyecto, es un problema grave de rendimiento. Porque tendría que estar leyendo el sitio fuente cada vez que un usuario accede a nuestro sitio. Lo ideal es separar el script donde realizamos el scraping y guardarlo en algún medio de almacenamiento en nuestro servidor como una base de datos y con una tarea programada. El sitio accedería a la información previamente obtenida por el script. Es un tema que abordaremos en el siguiente tutorial.
- El código fuente es funcional a la fecha de la publicación. Sin embargo, la página web fuente puede realizar cambios en sus vistas. Es recomendable revisar que el script este constantemente actualizado. Si es necesario, repetir el proceso de inspección del código fuente de las páginas de referencia.
Por favor, cuéntame que tal te pareció este tutorial. Si te fue de utilidad, ayúdanos a compartir este contenido para poder ayudar a más personas. Si tienes alguna duda u observación, estaré encantado de leerte e intercambiar opiniones para enriquecer este post.